您好,欢迎访问九游体育官网!TAG标签主页


今天(1月8日),作为“全球大模型第一股”的智谱,正式登陆港交所,首日开盘报120港元/股,截至发稿,最高涨超16%至135港元/股,市值近600亿港元。
这场“AI资本首秀”,并不是孤例。明天(1月9日),另一家国产AI大模型公司MiniMax,也将紧锣密鼓登陆港交所。
连续两天,两家中国AI大模型公司密集敲钟。这不仅是中国AI公司之间的竞速,也是全球AI资本大潮的缩影。
另一家大模型独角兽Anthropic,在完成130亿美元(约928亿人民币)F轮融资后,也被曝加速上市,估值剑指3000亿美元(约2万亿人民币)。
一边是中国企业密集冲刺,一边是美国巨头蓄势待发,全球AI的竞争维度,从技术暗战升级为资本搏杀。
而作为“全球大模型第一股”的智谱,不仅为缺乏市场公开估值的大模型行业,打下了第一个“估值锚点”,也为整个中国AI产业,打开了一扇价值重估的大门。
智谱的上市,不仅是中国AI企业首次在资本市场节奏上跑赢了OpenAI、Anthropic等美国巨头,也标志着全球资本的AI投资叙事正从“能力验证”迈入“规模扩张”的新阶段。
2025年12月,智谱新一代基座模型GLM-4.7在模型综合能力榜单Artificial Analysis登顶全球开源模型与国产模型双料榜首。
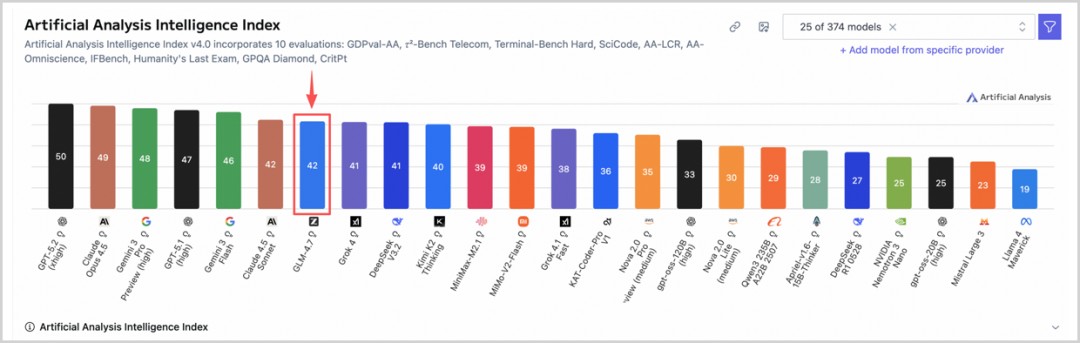
另外,在全球百万用户盲测的Code Arena(代码竞技场)上,GLM-4.7位列全球开源第一、国内第一,超过了GPT-5.2。

在全球大模型超市OpenRouter上,GLM-4.5/4.6的调用量稳居全球前10,付费API收入更超过其他所有国产大模型之和,也是不争的事实。
如果把大模型架构比作思维模式,那GPT的单向注意力机制,有点像走路时顾前不顾后。
但GLM架构的核心创新“双向上下文建模”,则像“眼观六路、耳听八方”,既能吃透前文信息,又能兼顾后文语境,处理语言任务时更加周全。
这种独特的设计,不仅让GLM在中文语境下有更强的理解力,也并不盲从Scaling Law法则,而是跳出了业内疯狂堆参数的怪圈,更强调鲁棒性、可控性和幻觉抑制性。
多数玩家心照不宣锁定C端,毕竟触达亿万消费者的赛道,天生就带着“流量变现”的光环。
像OpenAI的ChatGPT引爆全球后,迅速完成了从“现象级产品”到“AI操作系统”的蜕变,不仅直面消费者,还成为无数应用背后的隐形引擎,成为各行各业的“水电煤气”。
但在中国,B端才是线年,中国大语言模型市场规模约53亿,其中B端客户贡献47亿,C端客户仅占6亿。
(模型即服务)的商业模式,构建起“本地化部署+云端API服务”的双引擎业务结构。这份低调,引发了一个关于它商业模式的“误读”。
9家在用智谱;12000家企业客户,日均在智谱消耗4.2万亿token。MaaS模式,由此成为智谱高速增长的核心引擎。

像在马来西亚、新加坡等国家,由智谱帮助建立的国家主权大模型已正式落地,实现了中国大模型出海“零的突破”。
AI治理和基础设施建设中。而在高手如林的北美、欧洲开发者市场,智谱完成了另一场更具市场化意义的验证。
在官方报告中,明确将智谱列为“头号竞争对手”,视其为足以威胁OpenAI发展的竞争者。对手的“认证”,反而印证了中国AI的崛起。
而智谱云端MaaS业务的爆发式增长,成为上市后营收发力的核心支撑。GLM-4.7发布后,其MaaS ARR年化收入从2000万增至超5亿,10个月斩获25倍增幅,与Anthropic指数级增长同频。更超预期的是,2025年全年MaaS同比增速超900%,幂次增长态势显著优于海外龙头同期表现。
AI企业全球逐鹿的号角,也将是大国生产力和社会智能变革的新开端。这是一场关于未来智能的无限战争,而中国的“智谱们”,正在写下最具想象力的未来注脚。
